



AWS DynamoDB Analysen mit QuickSight und AWS CDK
Hi.
AWS DynamoDB ist eine extrem performante und skalierbare NoSQL Datenbank. Durch das fehlen eines Schemas können Daten, in DynamoDb Items genannt, extrem flexibel sein. Das erlaubt auch eine Art evolutionäre Weiterentwicklung der Items indem einfach neue Spalten angelegt werden können.
Das ganze hat aber einen Haken. Dadurch, dass wir uns nicht mehr in der Welt der relationalen Daten befinden, können wir keine relationalen Operationen mehr ausführen wie zum Beispiel Joins oder die üblichen relationalen Operationen wie COUNT, ORDER BY, GROUP by und viele mehr. Nun fragst du dich warum sollte ich zum Beispiel Joins ausführen können, die haben uns doch schon genervt bei den relationalen Datenbanken? Wir können Joins zum Beispiel bei Analysen gebrauchen. Ich versuche das zu erklären anhand eines Shops:
- Top X verkauften Produkte im Zeitraum von t1 bis t2 grouped by Geschlecht
In unserem Beispiel befinden sich die User und die verkauften Produkte jeweils in ihrer eigenen DynamoDB Tabelle und sind indirekt über eine userId verbunden. Denkbar wäre aber auch dass sich beide in der gleichen Tabelle, aber in unterschiedlichen Datensätzen bzw. Rows befinden. DynamoDB erlaubt keine Joins und somit können wir keine Beziehung zwischen verkauften Produkten und dem Geschlecht herstellen.
Die Lösung für das Problem ist AWS Athena, QuickSight, Lambda und S3. Mit einer Lambda werden die DynamoDB Items als flache JSON File in ein S3 gespeichert. Dann lassen wir Athena darauf zugreifen. QuickSight benutzt Athena dann als Datenengine um Joins, Analysen und Dashboards zu erstellen. Wie ihr das mit AWS CDK automatisiert und eine Beschreibung der verwendeten AWS Services folgen in den nächsten Abschnitten. Für die Ungeduldigen hier schonmal der Code
Zuvor möchte ich aber noch den Sponsor für diesen Blogpost und dem aufregenden Projekt um Analysen von DynamoDB Tabellen mittels QuickSight durchzuführen. Vielen Dank an TAKE2 dass ich in eurem agilen und motiviertem Team sein darf um so aufregende AWS CDK Aufgaben wie diese arbeiten zu können.
AWS DynamoDB
AWS DynamoDB ist eine gemanagte NoSQL Datenbank mit sehr guter Performance und Skalierung. Durch das managen der Datenbank von AWS entfällen aufwendige Administrative Aufgaben wie Installation oder Wartung. DynamoDB besitzt auch Backup Features wie on demand oder Point-in-Time Recovery.
In DynamoDB müssen die eingefügten Daten keinem festdefiniertem Schema folgen wie in etwa bei relationen Datenbanken. Das ist super flexibel und sehr nützlich, kann aber auch zu Problemen führen wie Unübersichtlichkeit oder Inkonsistenzen bei den Spaltennamen. Von daher empfehle ich nur bestimmte Spalten in der Tabelle zuzulassen. Das kann z.B. erreicht werden durch eine Schemavalidierung im Api Gateway oder der Verwendung eines GraphQL Schema in AWS AppSync.
AWS Athena
AWS Athena erlaubt das Querien von Daten. Zum Zugriff auf die Daten benutzt der Entwickler Standard-SQL als Query Language. Als Datenquelle können verschiedene AWS Services dienen wie S3, RedShift und seit neuestem auch DynamoDB. Der Vorteil an Athena ist, dass es Serverless ist und man sich somit direkt auf die Datenabfrage konzentrieren kann.
Um DynamoDB als Datenquelle für Athena zu setzen braucht man einen Lambda Connector. Der Connector schreibt dabei alle Items aus der Tabelle in einen S3 Bucket. Zum Glück bietet AWS eine SAM Lambda bereits an die den Job übernimmt. Diese Lambda heißt AthenaDynamoDBConnector
AWS QuickSight
AWS QuickSight ist ein Service zum Erstellen und Analysieren von Visualisierungen der Kundendaten. Die Kundendaten können dabei in AWS Services liegen wie S3, RedShift oder wie in unserem Fall in DynamoDB.
QuickSight kann zum jetzigen Zeitpunkt noch nicht direkt Daten von DynamoDB einlesen und es muss ein kleiner Zwischenschritt gemacht werden. Die DynamoDB Daten müssen in einem S3 Bucket z.B. als JSON exportiert werden. Dann kann QuickSight die sich im S3 befindenden Daten einlesen.
Um die Daten in den S3 Bucket zu schieben eignet sich der Ansatz eine AthenaDynamoDBConnector Lambda zu verwenden. Näheres darüber findest du im nächsten Abschnitt.
Quicksight bietet viele coole Funktionen zum Verarbeiten und Visualisieren von Daten die zum Beispiel aus DynamoDB kommen können. Auch lassen sich diese mit CDK als Code definieren.
Ich arbeite daran die erstellen QuickSight Analysen via CDK in Templates zu speichern um sie so cross account mäßig zugreifbar zu machen. Das ermöglicht dann Analysen auf einem dev account zu Erstellen und Testen und diese dann in den prod Account automatisiert zu via CDK zu deployn. Wie genau das alles von statten gehen soll erkläre im nächsten Blogpost.
AWS CDK
AWS CDK ist ein Open Source Framework zu Erstellung und Verwaltung von AWS Ressourcen. Durch die Verwendung von dem Entwickler vertrauten Sprachen wie TypeScript oder Python wird die Infrastructure as Code beschrieben. Dabei synthetisiert CDK den Code zu AWS Cloudformation Templates und kann diese optional gleich deployen.
AWS CDK erfährt seit 2019 ein stetigen Zuwachs von begeisterten Entwicklern und hat bereits eine starke und hilfsbereite Community die z.B. sehr auf Slack aktiv ist. Es gibt natürlich noch viel mehr zu sagen über AWS CDK und ich empfehle euch es zu erforschen. Schreibt mir, wenn ihr Fragen habt.
Mit AWS CDK habe ich einen hohen Automatisierungsgrad bei der Erstellung und Verwaltung des DynamoDB QuickSight Deployments erreicht. Dabei werden die benötigten AWS Ressourcen und dessen Konfigurationen schön als Code definiert und dann einfach ausgeführt. Und hier seht ihr ein Komponentendiagram:
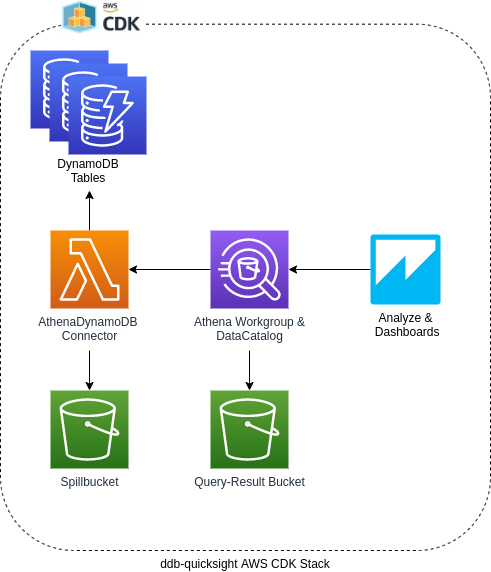
Den AWS CDK Code für das DynamoDB Athena Deployment findet ihr in meinem Repo. Unbedingt dort auch die Readme ansehen da diese viele wichtige Anweisungen und Informationen enthält. Leider konnte ich nicht alles in AWS CDK verfassen da z.B. die SAM Lambda AthenaDynamoDBConnector lässt sich nicht oder nur schwierig in AWS CDK übersetzen und sie muss bis jetzt noch manuel deployed werden.
Ausblick
Es wäre super cool wenn der AthenaDynamoDBConnector auch in AWS CDK erhältlich wäre. Auch scheinen mir die QuickSight Cloudformation Ressourcen noch sehr unausgereift da manches noch garnicht unterstütz wird wie z.B. das DataSet. Ein GitHub Issue wurde bereits schon erstellt.
Wie schon in der QuickSight Sektion erwähnt, arbeite ich daran die Analysen von QuickSight mittel CDK zu persistieren und dann Cross Account mäßig verfügbar zu machen. Meine Findings werde ich dann im nächsten Blogpost zeigen.
Zusammenfassung
AWS QuickSight ist ein spannendes Analysetool zum Auswerten von Daten in einer DynamoDB Tabelle. Daten sind ja das neue Gold und von daher ist es extrem wichtig Daten aus einer DynamoDB Tabelle verarbeiten zu können. Wenn dabei noch vertraute mechanismen wie SQL Queries, Aggregat Funktionen benutzt werden können ist das super. Auch bietet QuickSight coole graphische Lösungen zum Anzeigen von Analysen und Dashboards. Ich bin schon sehr darauf gespannt mehr damit zu arbeiten.
Vielen Dank auch an Jared Donboch für den extrem hilfreichen BlogPost Using Athena data connectors to visualize DynamoDB data with AWS QuickSight . Basierend darauf konnte ich so viel wie möglich automatisieren indem ich es in einen AWS CDK Stack verfasst habe.
Nochmal vielen Dank an TAKE2 für das Sponsoring dieses Blogposts.
An die tollen Leser dieses Artikels sei gesagt, dass Feedback jeglicher Art gerne gesehen ist. In Zukunft werde ich versuchen hier eine Diskussionsfunktion einzubauen. Bis dahin sendet mir doch bitte direkten Feedback über meine Sozial Media accounts wie Twitter oder FaceBook. Vielen Dank :).
Ich liebe es an Content Management Open Source Projekte zu arbeiten. Vieles kannst du bereits frei nutzen auf www.github.com/mmuller88 . Wenn du meine dortige Arbeit sowie meine Blog Posts toll findest, denke doch bitte darüber nach, mich zu unterstützen und ein Patreon zu werden:

