Hi.
AWS DynamoDB is an extremely performant and scalable NoSQL database. Due to the lack of a schema, data, called items in DynamoDb, can be extremely flexible. This also allows a kind of evolutionary development of the items by simply creating new columns.
But there is a catch. Because we are no longer in the world of relational data, we can no longer perform relational operations such as joins or the usual relational operations like COUNT, ORDER BY, GROUP by and many more. Now you ask yourself why should I be able to perform joins for example, they already bugged us with relational databases? We can use joins for example in analysis. I'll try to explain it with a store:
- Top X products sold in the period from t1 to t2 grouped by gender.
In our example the users and the sold products are each in their own DynamoDB table and are indirectly connected via a userId. However, it is also conceivable that both are in the same table, but in different data sets or rows. DynamoDB does not allow joins and so we cannot relate products sold to gender.
The solution to the problem is AWS Athena, QuickSight, Lambda and S3. Using a Lambda, we store the DynamoDB items as a flat JSON file in an S3. Then we let Athena access it. QuickSight then uses Athena as a data engine to create joins, analytics, and dashboards. How you automate this with AWS CDK and a description of the AWS services used will follow in the next sections. For the impatient ones, here is the code.
But before we got to the next section I would like to thank the sponsor for this blogpost and the exciting project to perform analysis of DynamoDB tables using QuickSight. Thanks to TAKE2 for letting me be part of your agile and motivated team to work on exciting AWS CDK tasks like these.
AWS DynamoDB
AWS DynamoDB is a managed NoSQL database with very good performance and scaling. Managing the database from AWS eliminates tedious administrative tasks such as installation or maintenance. DynamoDB also has backup features like on demand or point-in-time recovery.
In DynamoDB, the inserted data does not have to follow a fixed schema like in relational databases. This is super flexible and very useful, but can also lead to problems like confusion or inconsistencies in column names. Therefore I recommend to allow only certain columns in the table. This can be achieved for example by schema validation in Api Gateway or using a GraphQL schema in AWS AppSync.
AWS Athena
AWS Athena allows data to be queried. To access the data, the developer uses standard SQL as the query language. The data source can be various AWS services such as S3, RedShift and most recently DynamoDB. The advantage to Athena is that it is serverless, so you can focus directly on querying the data.
To set DynamoDB as data source for Athena you need a Lambda Connector. The connector writes all items from the table into an S3 bucket. Fortunately, AWS already provides a SAM Lambda that does the job. This lambda is called AthenaDynamoDBConnector
AWS QuickSight
AWS QuickSight is a service for creating and analyzing visualizations of customer data. The customer data can reside in AWS services like S3, RedShift or as in our case in DynamoDB.
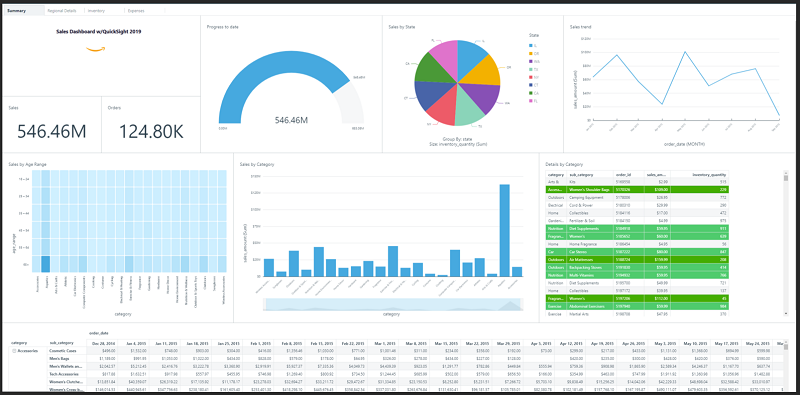
QuickSight cannot directly read data from DynamoDB at this time and a small intermediate step must be taken. The DynamoDB data has to be exported in a S3 bucket e.g. as JSON. Then QuickSight can read the data located in the S3.
To push the data into the S3 bucket the approach of using an AthenaDynamoDBConnector Lambda is suitable. You can read more about this in the next section.
Quicksight offers many cool functions for processing and visualizing data that can come from DynamoDB for example. You can also define them as code with CDK.
I am working on storing the QuickSight analyses in templates via CDK in order to make them cross account accessible. This will allow me to create and test analyses on a dev account and then deploy them automatically to the prod account via CDK. How exactly this should work will be explained in the next blogpost.
AWS CDK
AWS CDK](https://github.com/aws/aws-cdk) is an open source framework for creating and managing AWS resources. By using languages familiar to the developer such as TypeScript or Python, the infrastructure is described as code. In doing so, CDK synthesizes the code into AWS Cloudformation Templates and can optionally deploy them right away.
AWS CDK has been experiencing a steady increase in enthusiastic developers since 2019 and already has a strong and helpful community that is very active on Slack. There is of course much more to say about AWS CDK and I recommend you explore it. Drop me a line if you have any questions.
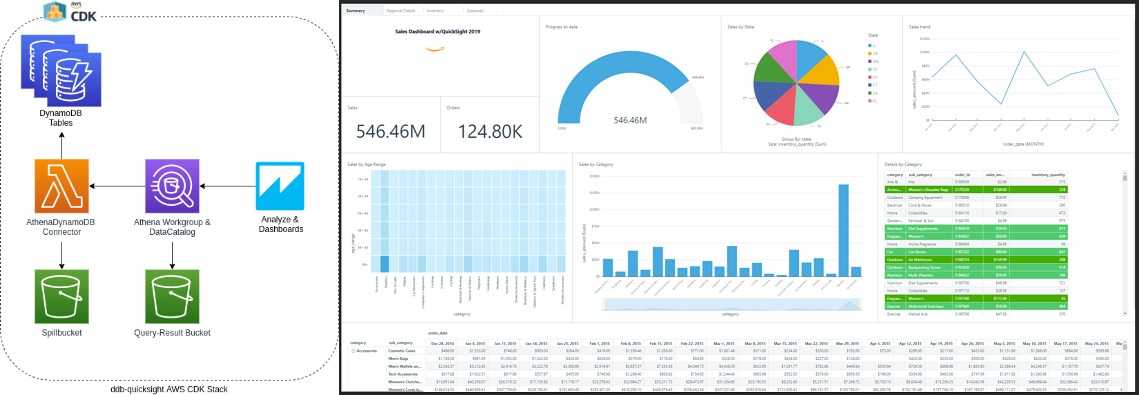
With AWS CDK, I have achieved a high level of automation in creating and managing the DynamoDB QuickSight deployment. This involves defining the required AWS resources and its configurations nicely as code and then simply executing them. And here you can see a component diagram:
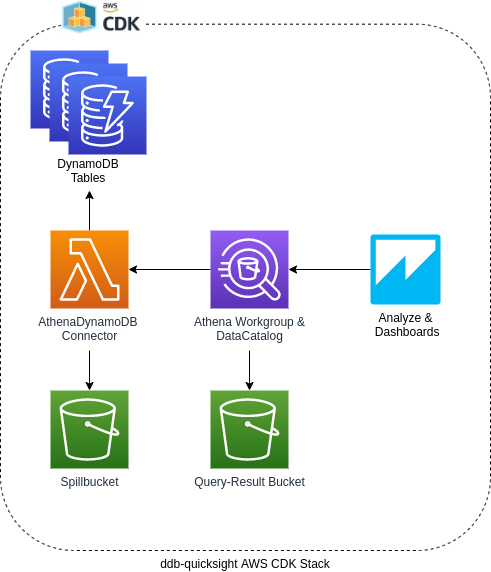
You can find the AWS CDK code for the DynamoDB Athena deployment in my repo. Be sure to check out the readme there as well since it contains a lot of important instructions and information. Unfortunately I couldn't write everything in AWS CDK because e.g. the SAM Lambda AthenaDynamoDBConnector is not or only difficult to translate in AWS CDK and it has to be deployed manually until now.
Outlook
It would be super cool if the AthenaDynamoDBConnector was also available in AWS CDK. Also, the QuickSight Cloudformation resources still seem very immature to me as some things are not supported at all like the DataSet. A GitHub Issue has already been created.
As mentioned in the QuickSight section, I am working on persisting the analytics from QuickSight using CDK and then making them available cross account wise. I will show my findings in the next blogpost.
Summary.
AWS QuickSight is an exciting analytics tool for evaluating data in a DynamoDB table. Data is the new gold and therefore it is extremely important to be able to process data that is difficult to process, for example in a DynamoDB table. If you can use familiar mechanisms like SQL queries and aggregate functions, that's great. Also QuickSight offers cool graphical solutions for displaying analyses and dashboards. I am very excited to be able to work with it more.
Thanks also to Jared Donboch for the extremely helpful BlogPost Using Athena data connectors to visualize DynamoDB data with AWS QuickSight . Based on that, I was able to automate as much as possible by composing it into an AWS CDK stack.
Thanks again to TAKE2 for sponsoring this blog post.
Thanks to the DeepL translater (free version) for helping with translating to english and saving me tons of time :).
To the wonderful readers of this article I'm saying that feedback of any kind is welcome. In the future I will try to include a discussion and comment feature here. In the meantime, please feel free to send me feedback via my social media accounts such as Twitter or FaceBook. Thank you very much :).
I love to work on Content Management Open Source projects. A lot from my stuff you can already use on https://github.com/mmuller88 . If you like my work there and my blog posts, please consider supporting me on Patreon:

