Hi
Storing data like JSON logs in DynamoDB is a great idea as DynamoDB is very scalable. In addition, it is easier to transfer data into a DynamoDB table using for example Lambda and AWS SDK. Also, it makes analyzing the logs easier for example the AWS Console offers great filtering options to search for specific so-called table items.
This all sounds very good but there is one hitch and that is the cost. As the number of items increases, so does the cost. So it would be advisable to delete the DynamoDB data from the table after a certain time, e.g. 30 days, and import it into an S3. The costs for S3 are much lower and it would even be possible to reduce them if you use a cheaper S3 tier like Glacier.
The question now is how you can do this most sophisticated? For me the combination DynamoDB Time To Live, DynamoDB Streams and Lambda which writes to an S3 bucket worked very well. In the following section, I will describe my solution.
Solution
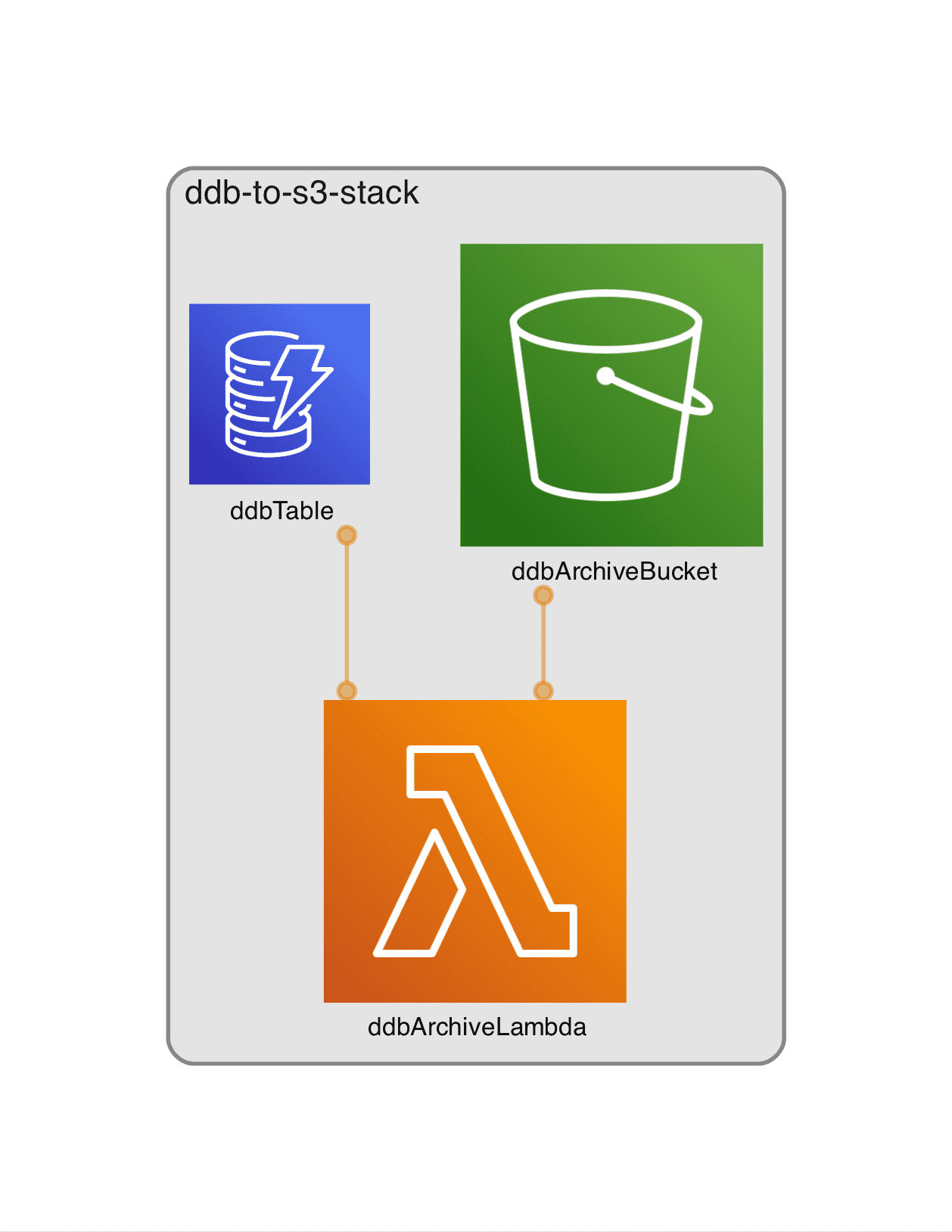
You can find the code in my GitHub repo https://github.com/mmuller88/cdk-ddb-to-s3 . As you can see the architecture in the title image is simple. DynamoDB Streams invokes a Lambda, which writes the deleted item away to S3. In my example, the DynamoDB items are JSON logs with few properties. In your case, the DynamoDB item can look different. But the basic concept should still the same!
By the way, if you are curious how I created the AWS Component Architecture Diagram, you can read it here.
const table = new ddb.Table(this, "table", {
partitionKey: { name: "systemId", type: ddb.AttributeType.NUMBER },
sortKey: { name: "timestamp", type: ddb.AttributeType.NUMBER },
stream: ddb.StreamViewType.OLD_IMAGE,
timeToLiveAttribute: "ttl",
})
const ddbArchiveBucket = new s3.Bucket(this, "ddbArchiveBucket")
const ddbArchiveLambda = new lambdajs.NodejsFunction(this, "ddbArchiveLambda", {
reservedConcurrentExecutions: 1,
environment: {
DDB_ARCHIVE_BUCKET_NAME: ddbArchiveBucket.bucketName,
},
})
table.grantStreamRead(ddbArchiveLambda)
spyderArchiveLogBucket.grantWrite(ddbArchiveLambda)
ddbArchiveBucket.addEventSourceMapping("archivelog", {
// max json document is 4 mb per file
batchSize: 10000,
maxBatchingWindow: core.Duration.minutes(5),
eventSourceArn: table.tableStreamArn,
startingPosition: lambda.StartingPosition.TRIM_HORIZON,
bisectBatchOnError: true,
})stream: ddb.StreamViewType.OLD_IMAGE is set because I am only interested in the items that have been deleted.
In the table definition a TimeToLive attribute was set with timeToLiveAttribute: 'ttl' . It is then important that your component which writes the data to DynamoDB always sets the ttl attribute. This is a timestamp that describes when the item should be deleted. In my project this was after 30 days.
Usually, you should only need one running Lambda to write the data away to S3 reservedConcurrentExecutions: 1. That serves as an additional safeguard against many unexpected invocations of Lambda.
The addEventSourceMapping part is probably the most exciting. What is pretty cool is that DynamoDB Streams provides a batching feature. The Lambda can then process the deleted items as a batch. That reduces the number of Lambda calls and therefore the costs. The default DynamoDB default batching is not quite ideal for our use case here so I used AWS Console and the Lambda call metrics to optimize it:
batchSize: 10000,
maxBatchingWindow: core.Duration.minutes(5),The batchSize with 10000 and the maxBatchingWindow are chosen maximally to call a Lambda really only every 5 minutes:


Super cool or? So the number of Lambda calls was massively reduced.
By the way, choosing the batch size with 10000 is ok in my case because they are JSON items and we stay under the maximum size of 4 MB per file if I write them away to S3. In your case this batch size could be to high. You have to try this out with testing. I just deleted 300 log items at once and it was still successfully written to S3 with a Lambda call.
With Athena and SQL queries the data in the S3 bucket can be inspected. How exactly that works I do not want to go into here. There are great tutorials that explain how Athena can be used to query for specific information in the S3 data such as JSON files.
Also I would like to mention that in some tutorials I have also seen the use of Kinesis Firehose. But I don't think you need it for your solution. DynamoDB Streams already has the ability to batch. But maybe it is another reason why Firehose was used. If you know why Kinesis Firehose might be useful write me!
Summary
Writing DynamoDB items away to S3 to save costs is super cool. Here I explained how you do it. Do you have any feedback on this post or other suggestions on what I can cover? Then let me know!
I love to work on Content Management Open Source projects. A lot from my stuff you can already use on https://github.com/mmuller88 . If you like my work there and my blog posts, please consider supporting me on Patreon:

