



DynamoDB Items nach S3 exportieren
Hi
Das Speichern von Daten wie JSON logs in DynamoDB ist eine super Idee da DynamoDB sehr skalierbar ist. Dazu kommt, dass es sehr einfach ist Daten in eine DynamoDB Tabelle zu transferieren mit z.B. Lambda und AWS SDK. Auch macht es das Analysieren der Logs leichter da z.B. die AWS Console tolle Filtermöglichkeiten bietet umd nach bestimmten sogenannten Tabellen Items zu suchen.
Das klingt alles sehr gut aber es gibt einen Harken und zwar die Kosten. Mit steigender Anzahl von Items steigen auch die Kosten. Es wäre also ratsam die DynamoDB Daten nach einer gewissen Zeit z.B. 30 Tagen aus der Tabelle zu löschen und in einem S3 zu importieren. Die Kosten für S3 sind wesentlich geringer und es wäre sogar potentiell möglich diese noch weiter zu reduzieren wenn ihr einen günstigeren S3 Tier wie Glacier verwendet.
Stellt sich jetzt natürlich die Frage wie ihr das am geschicktesten machen könnt? Für mich sehr gut geklappt hat die Kombination DynamoDB Time To Live, DynamoDB streams und Lambda welche dann in ein S3 Bucket schreibt. Im folgenden Abschnitt möchte ich meine Lösung gerne genauer beschreiben.
Solution
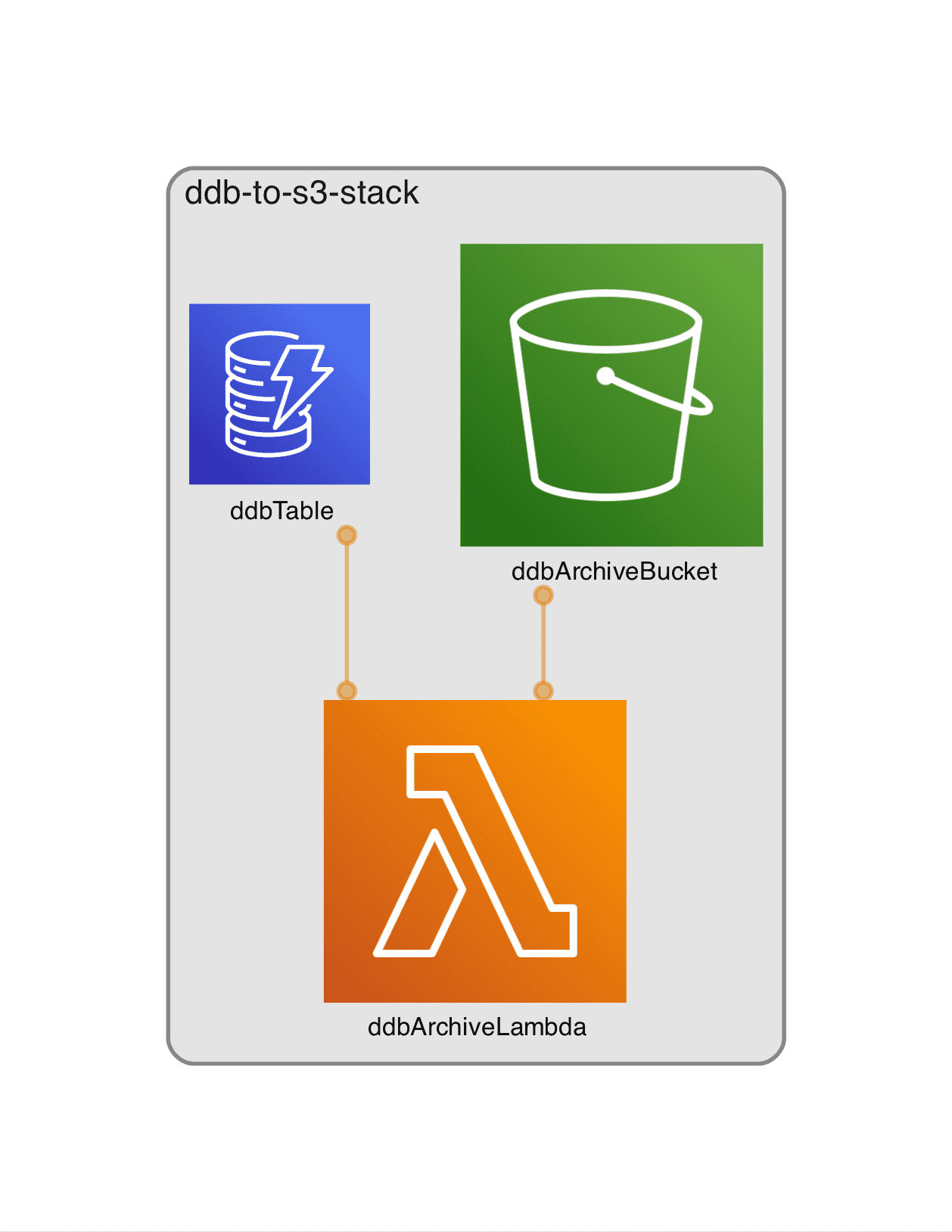
Ihr findet den Code natürlich in meinem GitHub repo https://github.com/mmuller88/cdk-ddb-to-s3. Die Architektur die ihr auch im Titelbild sehen könnt, ist recht einfach beschrieben. Es wird per DynamoDB streams eine Lambda getriggert, die die gelöschten Item nach S3 wegschreibt. In meinem Beispiel sind die DynamoDB Items einfach JSON logs mit wenigen properties. In eurem Fall kann das DynamoDB Item komplett anders aussehen. Das Grundkonzept müsste aber trotzdem stimmen!
By the way, if you're curious how I created the AWS Component Architecture Diagram, check it out here.
const table = new ddb.Table(this, "table", {
partitionKey: { name: "systemId", type: ddb.AttributeType.NUMBER },
sortKey: { name: "timestamp", type: ddb.AttributeType.NUMBER },
stream: ddb.StreamViewType.OLD_IMAGE,
timeToLiveAttribute: "ttl",
})
const ddbArchiveBucket = new s3.Bucket(this, "ddbArchiveBucket")
const ddbArchiveLambda = new lambdajs.NodejsFunction(this, "ddbArchiveLambda", {
reservedConcurrentExecutions: 1,
environment: {
DDB_ARCHIVE_BUCKET_NAME: ddbArchiveBucket.bucketName,
},
})
table.grantStreamRead(ddbArchiveLambda)
spyderArchiveLogBucket.grantWrite(ddbArchiveLambda)
ddbArchiveBucket.addEventSourceMapping("archivelog", {
// max json document is 4 mb per file
batchSize: 10000,
maxBatchingWindow: core.Duration.minutes(5),
eventSourceArn: table.tableStreamArn,
startingPosition: lambda.StartingPosition.TRIM_HORIZON,
bisectBatchOnError: true,
})stream: ddb.StreamViewType.OLD_IMAGE ist gesetzt da ich ja nur an den items interessiert bin welche gelöscht worden sind.
Bei der Table Definition wurde ein TimeToLive Attribut mit timeToLiveAttribute: 'ttl' . Es ist dann natürlich wichtig dass eure Komponente welche die Daten nach DynamoDB schreibt das ttl Attribut auch immer setzt. Das ist ein Timestamp der beschreibt wann das Table Item gelöscht werden soll. In meinem Projekt waren das nach 30 Tagen.
In der Regel solltet ihr nur eine laufende Lambda benötigen um die Daten nach S3 wegzuschreiben reservedConcurrentExecutions: 1. Das dient zusätzlich zur Absicherung, dass nicht unerwartet viele Aufrufe von Lambda stattfinden.
Die addEventSourceMapping ist wohl am spannendsten. Was ziemlich cool ist, dass DynamoDB Streams eine Batching-Feature bereitstellt. Die Lambda kann dann die gelöschten Items als Batch verarbeiten und dadurch kann die Anzahl der Lambda-Aufrufe reduziert werden und somit auch die Kosten. Das default DynamoDB default Batching ist aber nicht ganz ideal für unseren Use Case hier deswegen habe ich mittels AWS Console und den Lambda Aufruf Metriken diese optimiert:
batchSize: 10000,
maxBatchingWindow: core.Duration.minutes(5),Die batchSize mit 10000 und das maxBatchingWindow sind maximal gewählt um eine Lambda wirklich nur alle 5 Minuten aufrufen zu müssen:


Super cool oder? Somit wurde die Anzahl der Lambda Aufrufe massiv reduziert.
Übrigens die batch size mit 10000 zu wählen ist in meinem Fall ok da es ja JSON Items sind und wir unter der maximalen Größe von 4 MB pro File bleiben wenn ich diese nach S3 wegschreibe. In eurem Fall könnte diese batch size zu hoch sein. Das müsst ihr am besten mit Testen mal ausprobieren. Ich habe dafür z.B. einfach mal 300 Log Items auf einmal gelöscht und es wurde trotzdem erfolgreich alles mit einem Lambda Aufruf nach S3 weggeschrieben.
Mit Athena und SQL ähnlichen Queries lassen sich dann die Daten nun im S3 Bucket auch auswerten. Wie genau das funktioniert möchte ich aber hier nicht eingehen. Es gibt tolle Tutorials die erklären wie mittels Athena nach bestimmten Informationen in den S3 Daten wie JSON files gequired werden kann.
Auch noch möchte ich erwähnen, dass ich in manchen Tutorials auch die Verwendung von Kinesis Firehose gesehen habe. Ich glaube aber nicht, dass ihr das benötigt für eure Lösung. DynamoDB Streams hat schon die Möglichkeit zu Batchen. Vielleicht ist es aber auch ein anderer Grund warum Firehose verwendet wurde. Wenn ihr doch einen nützlichen Anwendungsfall für Firehose seht, sagt mir bitte Bescheid.
Zusammenfassung
DynamoDB Items nach S3 wegzuschreiben um Kosten zu sparen ist super cool. Hier habe ich euch erklärt wie ihr es machen könnt. Habt ihr Feedback zu diesem Post oder andere Vorschläge über was ich berichten kann? Dann sagt mir Bescheid!
Ich liebe es an Content Management Open Source Projekte zu arbeiten. Vieles kannst du bereits frei nutzen auf www.github.com/mmuller88 . Wenn du meine dortige Arbeit sowie meine Blog Posts toll findest, denke doch bitte darüber nach, mich zu unterstützen und ein Patreon zu werden:

